来自英伟达和MIT的研究团队,最近打造出了迄今最强的高清视频生成AI。
英伟达的研究人员开发了一种基于深度学习的系统,可以从每秒30帧的视频中生成高质量的慢动作视频。据称,这种方法已经超越其他同类的现有方案,可以让影视行业的创作者们更流畅地完成电影创作。

(图源:TechEBlog)
研究人员在年度计算机视觉和模式识别(CVPR)会议上展示了这一成果。
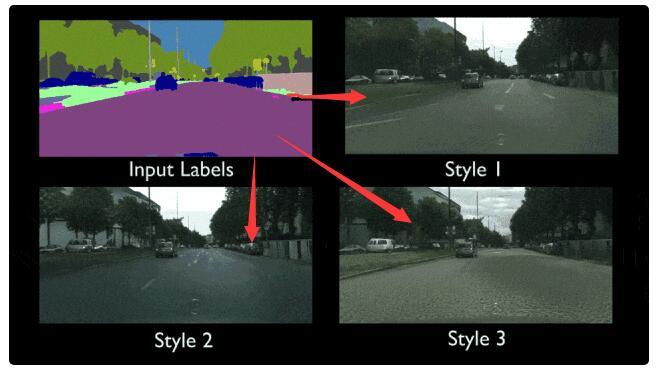
只要一幅动态的语义地图,你就可以获得和真实世界几乎一模一样的视频。换句话说,只要把你心中的场景勾勒出来,不用去实拍,电影级的视频就可以自动P出来。
使用NVIDIA Tesla V100 GPU和cuDNN加速的PyTorch深度学习框架,该团队在超过11,000个日常和体育活动视频中训练他们的系统,每秒240帧。经过训练,卷积神经网络预测了额外的帧。
“尽管可以用手机拍摄每秒240帧的视频,但以高帧速率录制所有内容是不切实际的,因为它需要大容量存储空间,并且对移动设备来说,耗电量实在太大。”该团队解释道。
该团队使用单独的数据集来验证其系统的准确性。他们使用了序列生成器和多尺度鉴别器来训练神经网络。生成器接收输入映射和前序帧,然后生成中间帧和Flow map。Flow map用于处理前序帧,然后与中间帧合并,从而生成最终帧。视频鉴别器接收Flow maps以及相邻帧以确保时间一致性。

(图源:Nvidia)
结果可以使以较低帧速率拍摄的视频看起来更流畅,更不模糊。
“我们的方法可以产生多个空间和时间相干的中间帧,”研究人员说。 “我们的多帧方法始终优于最先进的单帧方法。”
在创作的视频中,街景中的道路、车辆、建筑、绿植都可以自动生成,画面非常生动真实——而创作者只需提供大概的轮廓画面,简直不能更神奇!

此外,创作者还可以利用这一平台生成各种不同风格的视频,并临时改动画面内容,比如——把道路两侧的建筑全都变成树木。
在人物描绘方面,更是可以通过一个简单的素描草图,就能生成细节丰富、动作流畅的高清人脸,而人物的各种设置也是可以随机更换的。

这个团队,包括来自英伟达的Ting-Chun Wang、刘明宇(Ming-Yu Liu),以及来自MIT的朱俊彦(Jun-Yan Zhu)等。研究团队还给出了详细的训练指南,可以算是手把手教你如何自己训练出一个类似的强大神经网络。


















